背景
QQ 的“安全”策略
2021年1月18日,QQ 系被爆出扫描用户的浏览器历史记录,并对特定关键词进行了记录。
QQ 的公关回应说,这是安全策略。但其实,懂的都懂,这里不做过分推演。
某种意义上讲,目前各大互联网企业的竞争,实质上是数据的竞争。
数据越多越好
作为调参从业人员,从算法和模型角度来说,数据确实是越多越好。
数据越多,模型能捕获到的有用特征则更多。从特征状态空间,映射到实际标签的过程,会更顺畅、更准确。
我的数据谁做主
为什么大家会这么关注这个问题?有两方面的原因:
一:采集行为未经用户授权,且数据采集毫不相关。
二:日常生活中,有太多”精准“的推送。
早上刚和同事说想买 PS5,晚上各大 app 就开始展示 PS5 的商品广告。
用户可不管你用的什么方法,你拿了我的无关数据,展示了我心里想的东西。
啪的一下,两件事情就得到了关联。
现象背后的解释
心理的谬误
从心理学来讲,确实存在“孕妇效应”和“幸存者偏差”,会让我们错误地把两件事归因在一起。
即,怀孕的人,会突然发现,大街上怀孕的人变多了。但实际变多了吗?其实并没有,只是之前的注意力没在这里而已。
”幸存者“,则是那些发声的人。广告虽然会尽量投放给潜在顾客,但刚好命中前一秒有需求的,是少数。发声出来,让大家以为这是普遍现象。
算法也有“恐怖谷”
更多的则是,从用户体验层面,无理由的精准,着实会招致抵触。
在数据应用的早期,大家觉得这是个新鲜好玩的东西。但当推荐越来越离谱,仿佛读心术一般的,数据的“恐怖谷”效应也就出现了。
这和仿生人领域一样。当机器人越来越像人,人类感受到的不是亲切,而是害怕。推送太准确了,以至于让人发怵,从生理上抵触。
我模型牛逼,要什么解释性
而在研发层面,在做模型时,往往容易陷入参数狂热。
随着各种模型方法的支持,我们很容易将各类脑洞、各类特征、各类技巧糅合在一起,做出一个看起来还不错的结果。
但其实,我们很难解释,是哪部分带来的效果。是深度学习的网络结构,还是交叉几轮找不着北的特征,抑或是那不起眼的坐标信息?
大多数情况,我们给不了解释。
同行与监管的挑战
为了解决数据滥用、模型黑盒问题,业界正在发生变化:
软件提供者层面
iOS在14的版本更新中,有一个最显著的变化,引起了我的注意:系统在做应用推荐时,会给出推荐的理由。
而这,在此前的版本都是没有的。
例如连上蓝牙耳机时,屏幕的下方会显示:推荐xx音乐,因为连上蓝牙时经常这么做。
监管层面
蚂蚁上市告吹,马已经服。金融时报这样评价:
同时,大数据、人工智能等技术易导致“算法歧视”,严重损害特殊群体利益。相较于传统歧视行为,算法歧视更难约束。
其一,算法歧视维度多元。传统歧视行为通常依据性别、学历等显著外在特征,但算法能挖掘更深层次的隐形特征作为依据。
其二,算法歧视形式隐蔽。基于种族、性别、民族等特征的歧视行为被法律禁止,但自动化决策可利用“算法的不可解释性”规避职责,在不触犯现有法律规定的情况下,侵犯消费者合法权益。
尤其是当某一个大型互联网企业拥有涉及数亿消费者天量数据信息的情况下,即使从个体和逐笔看,其数据来源和使用均获得了消费者授权,但从总体看,可能存在“合成的谬误”,这些数据在总体上具有公共品性质,其管理、运用并非单一消费者授权就能解决其合法性问题。
这说明,监管已经注意到这个层面。且他们的认知很专业,抓住了问题的核心:无法解释的算法,隐藏在超参数背后的歧视,将会侵犯我们每个人的权益。
这次他们没有“喝茶看报打哈哈”。
数据来源需合法合规,模型解释也应该有所依据。
模型的可解释性,必须提上议程。
下面内容比较生涩,我尽量做到深入浅出,小白看了懂大概,同行看了知方法。
我们需要可解释性
可解释的3大必要性
-
对于用户:用户需要知道,你有没有“偷窥”他的隐私,是否有私底下采集用户数据,用于歧视性定价等。
这会影响用户忠诚度和品牌美誉度。
如果总是很“精准”地推一些东西,用神经网络或者是组合特征、泛人群特征,用户实际是会很懵逼的。
信息不对称的情况下,他会直接联想到最近的行为,从而产生被监视的感觉。
-
对于监管,监管部门有责任掌握细节,防止信息的滥用与风险的滋生。
就像针对蚂蚁金服的调查:用户的多维度数据被企业用来谋求更大利益,滋生出巨大的金融系统性风险。
-
对于业务,业务方需要知道每个模型背后的原理,以便更好的做出决策。
一些并不面向前端用户的项目,业务方需要知道手底下发生的事情,以便做到能够响应变化。
模型说:a 变大,则 b 会变小。那么,当 b 变大时,业务就可以通过调大 a,进而控制 b 变小。
可解释的4种原理
第一种,人工的规则。用人工观察的规则,来确保不会有问题。
第二种,用可解释的模型。用决策树,逻辑回归等,将权重落在上面,进行计算。
第三种,用简单模型解释复杂模型的结果。用魔法打败魔法。将难以解释的模型,用第二种拟合结果,判断黑盒内的内容。
第四种,基于样本的解释。取一两个例子,进行结果的阐释。
各种方式优缺点对比
第一种的人工规则,在前期有很大的作用,可当作基线模型。但一般会随着时间的流逝,产生数据偏移。或者是被黑产察觉利用。
第二种,能有一定效果,但是从拟合的效果上说,没有深度模型和集成模型好,且不能很好处理非线性的特征。
第三种,可解释性不强,但是可以提供很好的拟合效果,用于结果的判定。
第四种,从样本角度进行解释。优点是能产生很深刻的印象,缺点是每个样本都要单独解释。
常见的2种模型诊断方法
以下两类模型,是检索“机器学习 解释”,最容易跳出来的两类。我们从其优缺点分析,结合业务目标,进行一次梳理。
LIME
官方文档地址 https://github.com/marcotcr/lime
很多文章都写过如何使用LIME了,这里就不再赘述,上方的官方文档里有详尽的文档。

工作原理
和全局的模型解释不同,LIME 侧重于局部。
LIME 拉近镜头,解释局部发生的情况。
它通过模拟样本点的周围点,然后用一个简单的模型,来生成同样的结果。
其工作流程如下:
- 选择黑盒模型想预测的结果点
- 采样生成类似数据集,并让黑盒预测结果
- 根据需要解释的样本,对采样的结果赋予权重
- 用新样本,训练一个带权重,有解释性的新模型
- 通过新的、局部的模型,来对结果进行解释
需要注意的点:LIME根据每个特征,独立生成新样本。
优点
即使替换了整体的预测模型,仍然能用 LIME 进行局部的解释。
缺点
更擅长于解释分类特征,而不是数值特征。
相邻域没有明确的定义。
解释模型的选取,具有主观性。
结果不稳定。不同的解释模型,会产生不同的结果。
使用体验
从实际使用的感受来说,LIME 方法对于 NLP 和图像问题的解释较为直观。数值上的解释,波动较大。
SHAP
官方文档地址 https://shap.readthedocs.io/en/latest/
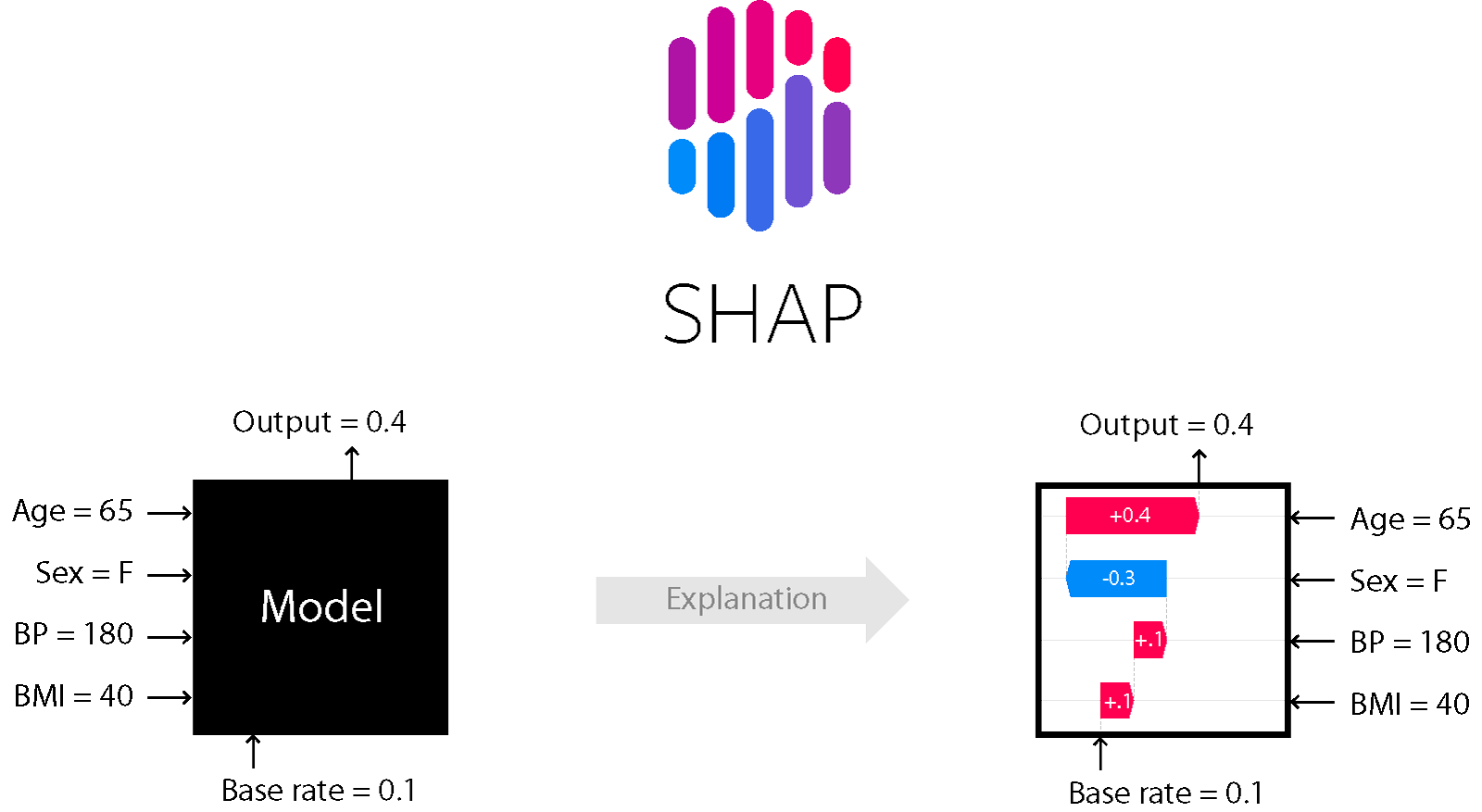
工作原理
SHAP 归因来源于博弈论的 shapely 理论,计算特征的边际贡献情况。
像线性模型,特征的贡献=特征的权重*特征值
shapley 值则是所有特征候选集的边际贡献。
shapley 方法是唯一一个满足效率、对称以及可加性的模型解释方法。
优点
所有特征均纳入计算。
允许特征之间的对比研究。
缺点
计算耗时。
返回权重,而不是预测结果。
需要拟合数据,不能直接通过模型得到。
容易受假数据干扰。
使用体验
这个方法,个人的使用体验是:反直觉。
从逻辑上来讲,它是最严密的,整体的结果来看,也具备可解释性,但是当你看到单个样本时,就开始出现玄学了。
波动幅度离谱,且人工感觉相似的样本,权重比还不尽相同,甚至是天差地别。
总结
这两种方式,离业务都还有一定距离。工程师能看懂,业务不一定能理解。
正确的处理方式
模型并不是越复杂越好,也是不是越准确越好。
面向用户或者面向监管,简单规则和可解释模型,基本能满足业务要求。
更深层次的,特征巨多,或者是想找到决策支撑点的,可考虑集成模型、深度模型。
急需解决的点
数据支撑业务,需要回答以下三点:
-
发生了什么?
-
什么原因导致的。
-
现状是什么。
-
-
影响了哪些用户?
- 正向的有哪些。
- 负面的有哪些。
-
未来会是什么样子?
- 如果不做干预,未来的数据将会是什么样子。
- 如果要做干预,从哪些地方切入,影响哪些人。
- 量化以上指标。
理想的状态:
如果我们能告诉业务,目标 a 受 b 的影响。提高 b,将会影响的用户群,最后作用到到 a 上,将会有多少的改变。
目前来看,基于案例的假设解释:“如果xxx,则xxx”,更贴近我们的目标。
参考资料
- Comparison between SHAP (Shapley Additive Explanation) and LIME (Local Interpretable Model-Agnostic Explanations)
- Interpreting an NLP model with LIME and SHAP
- Idea Behind LIME and SHAP
- https://christophm.github.io/interpretable-ml-book/